Nedávno jsem u jednoho zákazníka řešil nasazení Supervisor clusteru. Celkem triviální věc, řeknete se si, ale narazili jsme na několik věcí, které zatím nebyly plně zdokumentované v žádném KB.
Nasazení v první fázi probíhalo celkem normálně.
- Cluster s NSX
- Zákazník používá NSX, resp licenčně má VCF, ale instalované po částech na verzi vSphere 8.
- Storage policies
- I když zákazník nepoužívá vSAN, pro nasazení Tanzu (vSphere Kubernetes Services) je potřeba mít vytvořené Storage policy, aby K8S veděl kam umísťovat persistentní objekty.
- Musíte vytvořit Tagy pro Storage policies
- Přiřadit tyto Tagy odpovídajícím Datastores, aby při výběru Storage policy byl alespoň jeden Datastore „Compatible“
- Vytvořit Storage Policies, pokud nemáte vSAN, budou založeny jen na Tag based placement.
- Load Balancer
- Musíte si při vytváření Supervisor vybrat, zda budete používat NSX load balancer, nebo máte AVI. AVI se licencuje zvlášť, ale má více funkcionalit. Musíte si vždy udělat rozvahu, zda se Vám to vyplatí či nikoli.
- Zákazník si vybral „jen“ NSX.
- 3 IP subnety, které jsou routovatelné
- 1 pro Supervisor MGMT – lze použít VDS portgroup.
- 5 po sobě jdoucích IP adres
- 1 pro Ingress – Služby, které budou publikované ven přes LB
- 1 pro Egress – přístup všech kontejnerů a TKG clusterů do internetu „SNAT“
- 1 pro Supervisor MGMT – lze použít VDS portgroup.
- 2 IP subnety pro interní K8S konektivitu
- 1 subnet pro K8S konektivitu Supervisor Services podů a TKG clusterů
- 1 subnet pro K8S service objekty
- Subnety se nesmí překrývat s jinými supervisor subnety
Ve chvíli kdy spustíte Wizarda a zadáte tam všechny potřebnosti, tak už můžete pouze sledovat, co se všechno děje.
vCenter má službu EAM, která má vše na starosti.
- vygeneruje hesla pro root účet v rámci Supervisor Control VMs. Toto heslo si můžete pro troubleshooting zjistit, když se příhlásíte na vCenter pomocí root a spustíte následující příkaz:
-
/usr/lib/vmware-wcp/decryptK8Pwd.py
-
- Z OVF vytvoří 1/3 Supervisor VM
- To jestli vytvoří 1 nebo 3 záleží na tom, zda vyberete „HA“ režim či nikoli. Toto je ale dostupné až ve verzi 9. V předchozích verzích vždy vytvářel 3.
- Po startu Supervisor VM vytvoří mezi nimi K8S control plane cluster
- Obdobně jako kubeadm init
- kubeadm join
- V Supervisor Control Plane VMs se následně začnou spouštět kontejnery pro obsluhu
- Container Storage Interface
- Cert Manager
- Network Operator
- NSX-NCP
A právě při spouštění některých služeb, jako jsou CSI a NSX-NCP začne Supervisor komunikovat s vCenter a NSX managerem.
Další kroky, které nastanou (by měly nastat):
- vytvoření Segmentů, do kterých se připojí Supervisor VM a pomocí kterých komunikují K8S pody mezi sebou
- Vytvoření LB service v NSX
- Vytvoření DFW pravidel
- Konfigurace ESX hostů jako K8S worker node.
Vzhledem k tomu, že další kroky už provádí SV, tak je pro něj nutná konektivita s vCenter a NSX a k tomu se využívají DNS názvy. U tohoto kroku jsme se dostali do problému, protože překlad DNS nám z nějakého problému drhnul. Nutno zmínit, že pokud používáte doménu s koncovkou .local, tak musíte zadat jako search domain do Wizarda k vytváření Workload Management.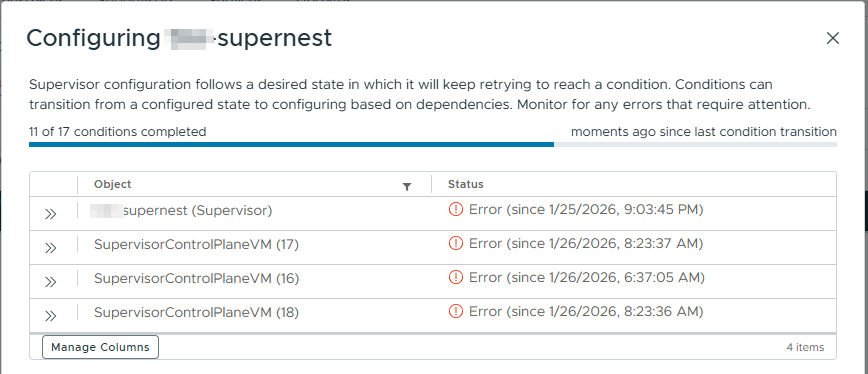
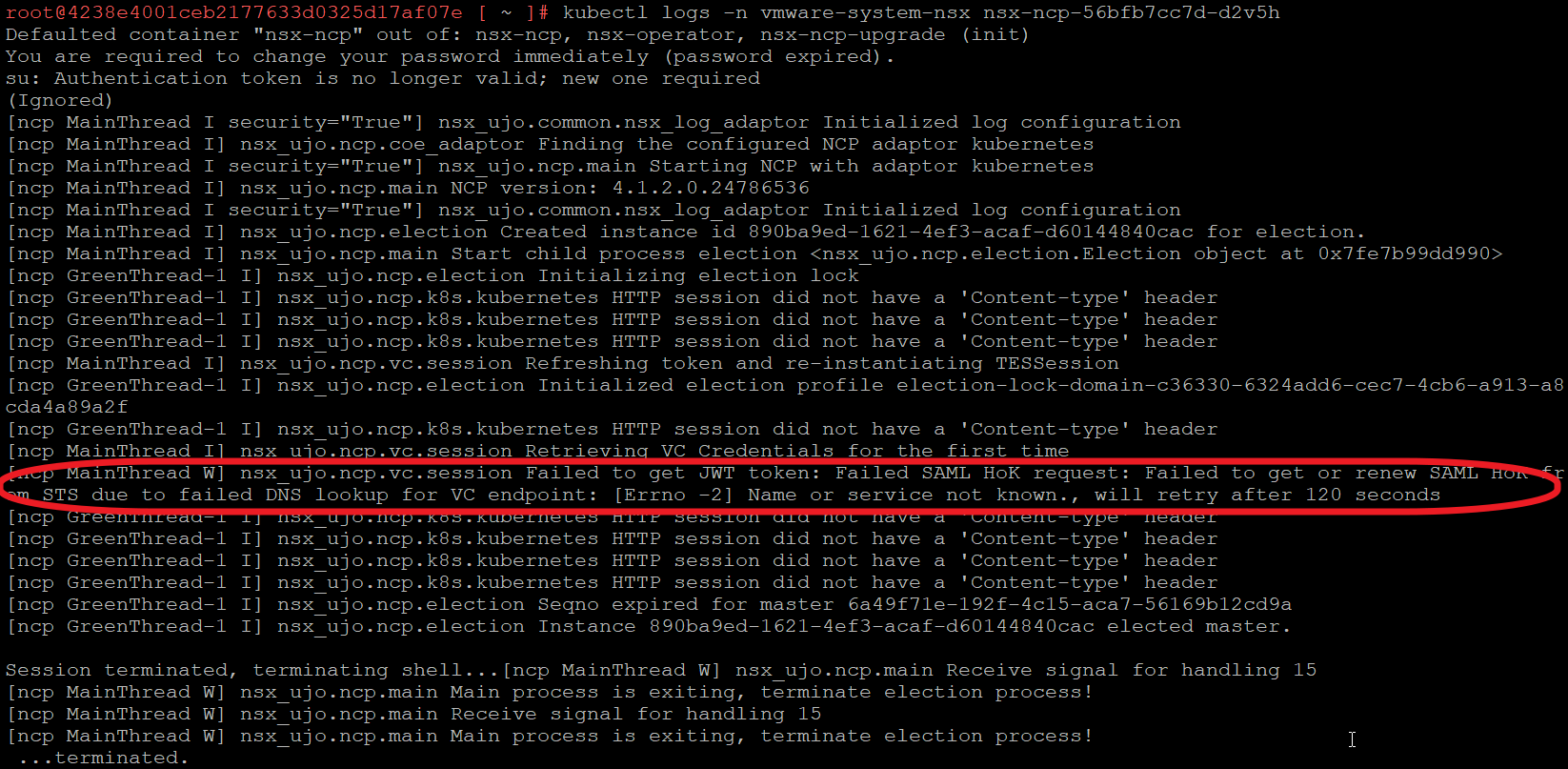
Když jsme se připojili do SV, tak klasická kontrola pomocí ping a curl prošla. Což spoustu KB zmiňuje, že máte vyzkoušet.
https://knowledge.broadcom.com/external/article/389329/vspherecsicontroller-pods-and-nsxncp-pod.html
Co ale dělat, když toto projde a NSX-NCP je stále ve stavu CrashLoopBackOff?
Se supportem jsme se dostali o kus dále:
alpine:~# dig vcenter.mojedomena.local A ; <<>> DiG 9.18.41 <<>> vcenter.mojedomena.local A ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53111 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;vcenter.mojedomena.local. IN A ;; ANSWER SECTION: vcenter.mojedomena.local. 1 IN A 192.168.10.6 ;; Query time: 0 msec ;; SERVER: 192.168.10.1#53(192.168.10.1) (UDP) ;; WHEN: Fri Jan 02 11:26:33 CET 2026 ;; MSG SIZE rcvd: 66 alpine:~# dig vcenter.mojedomena.local AAAA ; <<>> DiG 9.18.41 <<>> vcenter.mojedomena.local AAAA ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 32530 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;vcenter.mojedomena.local. IN AAAA ;; AUTHORITY SECTION: . 0 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2026010200 1800 900 604800 86400 ;; Query time: 40 msec ;; SERVER: 192.168.10.1#53(192.168.10.1) (UDP) ;; WHEN: Fri Jan 02 11:26:21 CET 2026 ;; MSG SIZE rcvd: 125
DNS
Problém je v tom, že pokud DNS server není pro doménu autoritativní, tak se může stát, že dotaz na neznámý záznam předá na nadřazený DNS server. Pokud takový nadřazený server je až root DNS, tak tam rozhodně doména .local nemá co dělat a skončí to odpovědí NXDOMAIN.
Se supprotem jsme ještě řešili proč se toto děje jen pro NSX-NCP. Další test, který to trochu osvětluje.
root [ / ]# tdnf install python3-pip
root [ / ]# pip install eventlet==0.33.3
root [ / ]# python3
>>> import socket
>>> import eventlet
>>> socket.create_connection(("vcenter.mojedomena.local", 443), 5)
<socket.socket fd=3, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('192.168.250.20', 54718), raddr=('192.168.10.6', 443)>
>>> eventlet.monkey_patch()
>>> socket.create_connection(("vcenter.mojedomena.local", 443), 5)
Traceback (most recent call last):
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 456, in resolve
return _proxy.query(name, rdtype, raise_on_no_answer=raises,
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 412, in query
return end()
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 391, in end
raise result[1]
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 372, in step
a = fun(*args, **kwargs)
File "/usr/lib/python3.10/site-packages/dns/resolver.py", line 1371, in query
return self.resolve(
File "/usr/lib/python3.10/site-packages/dns/resolver.py", line 1328, in resolve
timeout = self._compute_timeout(start, lifetime, resolution.errors)
File "/usr/lib/python3.10/site-packages/dns/resolver.py", line 1084, in _compute_timeout
raise LifetimeTimeout(timeout=duration, errors=errors)
dns.resolver.LifetimeTimeout: The resolution lifetime expired after 5.106 seconds: Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'; Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'; Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'; Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'; Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'; Server Do53:127.0.0.53@53 answered udp() got an unexpected keyword argument 'ignore_errors'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.10/site-packages/eventlet/green/socket.py", line 44, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 549, in getaddrinfo
qname, addrs = _getaddrinfo_lookup(host, family, flags)
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 522, in _getaddrinfo_lookup
raise err
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 511, in _getaddrinfo_lookup
answer = resolve(host, qfamily, False, use_network=use_network)
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 464, in resolve
raise EAI_EAGAIN_ERROR
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 511, in _getaddrinfo_lookup
answer = resolve(host, qfamily, False, use_network=use_network)
File "/usr/lib/python3.10/site-packages/eventlet/support/greendns.py", line 464, in resolve
raise EAI_EAGAIN_ERROR
socket.gaierror: [Errno -3] Lookup timed out
Protože v DNS RFC (https://www.ietf.org/rfc/rfc4074.txt) je zmíněno:
Many existing DNS clients (resolvers) that support IPv6 first search for AAAA Resource Records (RRs) of a target host name, and then for A RRs of the same name. This fallback mechanism is based on the DNS specifications, which if not obeyed by authoritative servers, can produce unpleasant results. In some cases, for example, a web browser fails to connect to a web server it could otherwise reach. In the following sections, this memo describes some typical cases of such misbehavior and its (bad) effects.
A toto je případ NSX-NCP, kde se použije eventlet.monkey_patch(), kdy se bude chovat k DNS velmi striktně. Tudíž nejprve AAAA a pak A záznam.
Řešení jsou 2. Jeden Workaround, který funguje jen do dalšího update Supervisoru, spočívá v úpravě specifikace NSX-NCP deploymentu těsně poté, co se začnou vytvářet všechny obslužné deploymenty.
root@423826f144b646d762b12a7399ac0ddd [ ~ ]# kubectl -n vmware-system-nsx get deployment/nsx-ncp -oyaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "5"
kubectl.kubernetes.io/last-applied-configuration: |
...
generation: 5
labels:
component: nsx-ncp
tier: nsx-networking
version: v1
name: nsx-ncp
namespace: vmware-system-nsx
resourceVersion: "9178866"
uid: e9759f64-754b-4d14-a3b6-91f66029161d
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
component: nsx-ncp
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: "2025-12-10T11:30:18Z"
last-sync: "1763989124.2055643"
prometheus.io/port: "8001"
prometheus.io/scrape: "true"
creationTimestamp: null
labels:
component: nsx-ncp
tier: nsx-networking
version: v1
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: component
operator: In
values:
- nsx-ncp
topologyKey: kubernetes.io/hostname
containers:
- env:
- name: EVENTLET_NO_GREENDNS <===============
value: "yes" <===============
- name: NCP_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: NCP_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
Druhé řešení by mělo být persistentní a to, zajistit aby DNS server nepřeposílal AAAA záznamy mimo. Nastavit jej jako Autoritativní pro vaši .local doménu.
MTU
Při simulaci tohoto problému jsme se pak dostali k druhé věci, která na první pohled nebyla vůbec jasná.
Museli jsme vytvořit nové prostředí, ve kterém bychom mohli celou situaci nasimulovat. Když jsem to zkoušel u sebe, tak se mi to nedařilo, ale neměl jsem tam úplně všechny prvky k dispozici. Zejména Fortigate, který obsluhoval DNS. Tak jsme se rozhodli ke kroku, vytvořit Nested prostředí nad stávajícím clusterem, abychom nemuseli shánět další 4 ESX hosty. Ve verzi 8 totiž Supervisor vyžaduje 3 Control Plane VM, tzn. bez 4 hostů v clusteru Vás nepustí průvodce dál.
Hosty vytvořeny, připojeny do vCenter, NSX nakonfigurován. Jakmile jsme ale chtěli udělat testovací VM, která bude komunikovat s vCenter, tak jsme narazili na problém. ICMP prošlo, curl na HTTP prošlo – přišla odpověď. Ale jakmile jsme se pokoušeli navázat HTTPS spojení, tak to končilo neúspěchem. S jinou VM, ve stejné síti, ale mimo Nested prostředí vše fungovalo.
Dlouho jsem si lámal hlavu, v čem je to prostředí jiné. Bylo to nested, ale těch jsem vytvořil za celou svou dobu s VMware spoustu a nikdy jsem se s tímto problémem nesetkal. Přemýšlel jsem i nad omezenými instrukčními sadami nových procesorů a porovnával, co VM dostávají v jiných ESX hostech.
Jak nadpis napovídá, problém byl v MTU. Kdy Nested hosty byly připojené do jiné Overlay VLAN a MTU routeru mezi segmenty zapomnělo být změněno a zůstalo na 1500.
Jak se to projevovalo jsem zaznamenal při zachytávání packetů
12:14:06.524329 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [S], seq 2119065766, win 64240, options [mss 1460,sackOK,TS val 3900574725 ecr 0,nop,wscale 7], length 0
12:14:06.525493 IP vcenter.mojedomena.local.https > 192.168.250.11.59648: Flags [S.], seq 3546398388, ack 2119065767, win 28960, options [mss 1460,sackOK,TS val 1399004370 ecr 3900574725,nop,wscale 8], length 0
12:14:06.525602 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [.], ack 1, win 502, options [nop,nop,TS val 3900574727 ecr 1399004370], length 0
12:14:06.528653 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [P.], seq 1:518, ack 1, win 502, options [nop,nop,TS val 3900574729 ecr 1399004370], length 517
12:14:06.529641 IP vcenter.mojedomena.local.https > 192.168.250.11.59648: Flags [.], ack 518, win 118, options [nop,nop,TS val 1399004374 ecr 3900574729], length 0
12:14:06.543649 IP vcenter.mojedomena.local.https > 192.168.250.11.59648: Flags [P.], seq 1449:1889, ack 518, win 118, options [nop,nop,TS val 1399004388 ecr 3900574729], length 440
12:14:06.543780 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [.], ack 1, win 502, options [nop,nop,TS val 3900574745 ecr 1399004374,nop,nop,sack 1 {1449:1889}], length 0
12:14:38.379354 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [F.], seq 518, ack 1, win 502, options [nop,nop,TS val 3900606580 ecr 1399004374,nop,nop,sack 1 {1449:1889}], length 0
12:14:38.380200 IP vcenter.mojedomena.local.https > 192.168.250.11.59648: Flags [F.], seq 1889, ack 519, win 118, options [nop,nop,TS val 1399036224 ecr 3900606580], length 0
12:14:38.380357 IP 192.168.250.11.59648 > vcenter.mojedomena.local.https: Flags [R], seq 2119066285, win 0, length 0
Důvod jsem zvýraznil a je hned v první řádku. Při sestavování TCP session klient na začátku oznámí, jaké MTU může posílat a přijímat. Toto provede jen na základě nastavení na síťové kartě/OS. Bez kontroly po cestě.
Jakto, že ICMP a HTTP prošlo a problém byl až s HTTPS?
ICMP a HTTP posílají relativně malé pakety, které se do 1400B okna vejdou bez problémů – nezkoušel jsem přijímat obrázky, tam by se to asi projevilo, ale testujte obrázek z CLI 🙂
HTTPS chce hned na začátku komunikace posílat Certifikát a ten se už rozdělí do velikosti 1460 B jak je na začátku TCP sync, ale když se do toho zakomponuje Geneve, který má sám o sobě minimálně 54B režii, tak se dostáváme mimo 1500 MTU nastavené na routeru a ten to zahazoval.
Takže kontrola ICMP paketu 1600+ vše prozradila, přenastaveno na jumbo 9126 a voila, vše začalo fungovat.
Takže Always DNS a kontrolujte si MTU. Opravdu na tom záleží a není to jen něco, co si síťaři vymýšlí.