Při nasazování vCenter Server Apliance si volíte, jaké zdroje má vCenter k dispozici. Nejsou to náhodně zvolené hodnoty, ale jsou voleny s ohledem na množství hostů, které bude vCenter spravovat. Někdy se ale stane, že dojde místo na některém z přidělených disků a vCenter přestane vykonávat svou práci. Pak to může po přihlášení do vSphere Web Client vypadat třeba takto:
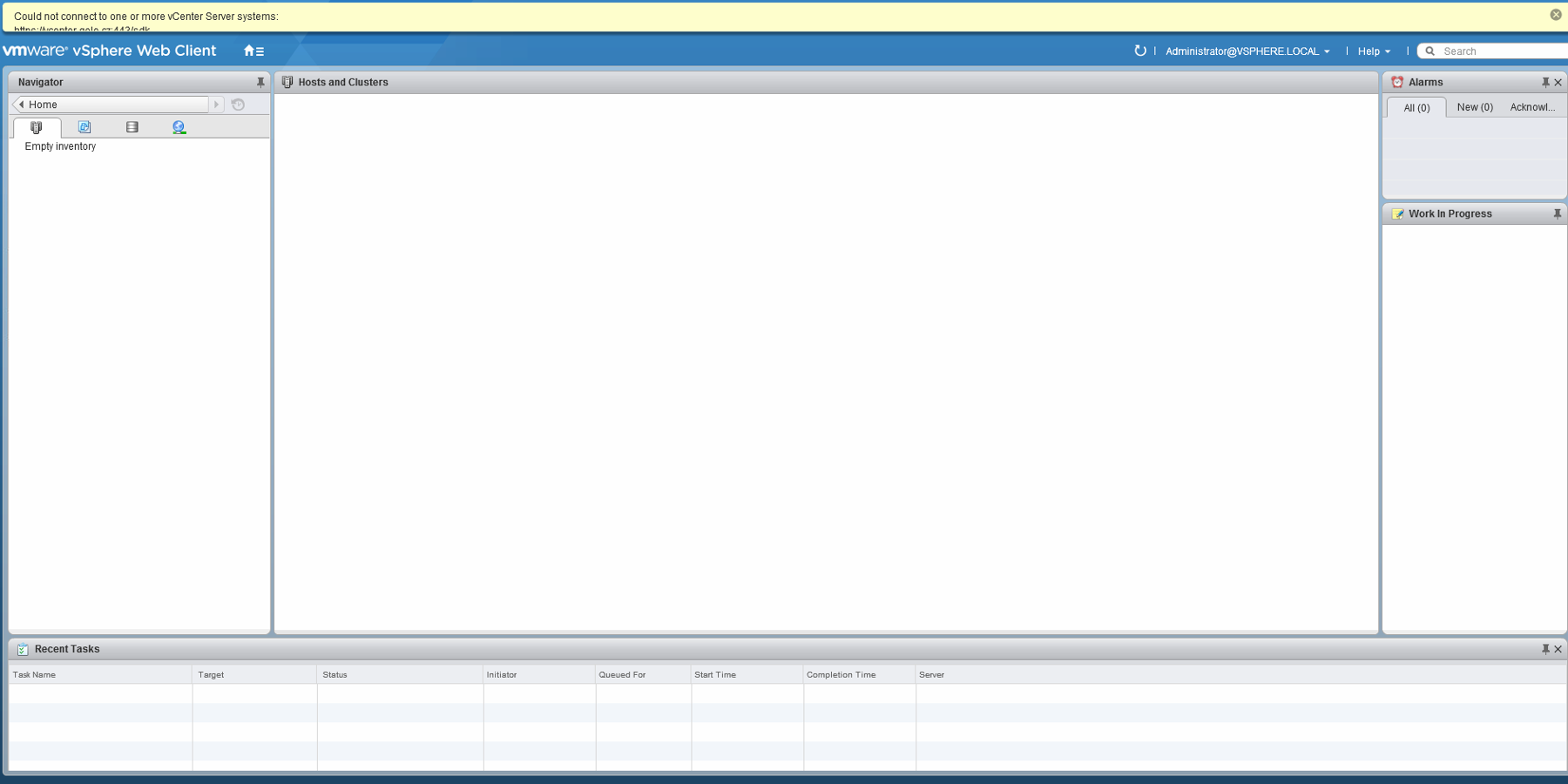
První cesta za poznáním, co se děje, pak vede do vCenter Server Appliance Web Console (VAMI) – (https://FQDN-nebo-IP-adresa-vCSA:5480), zde už vidíme první indícii, proč vCenter přestal pracovat:
The /storage/seat filesystem is out of disk space or inodes
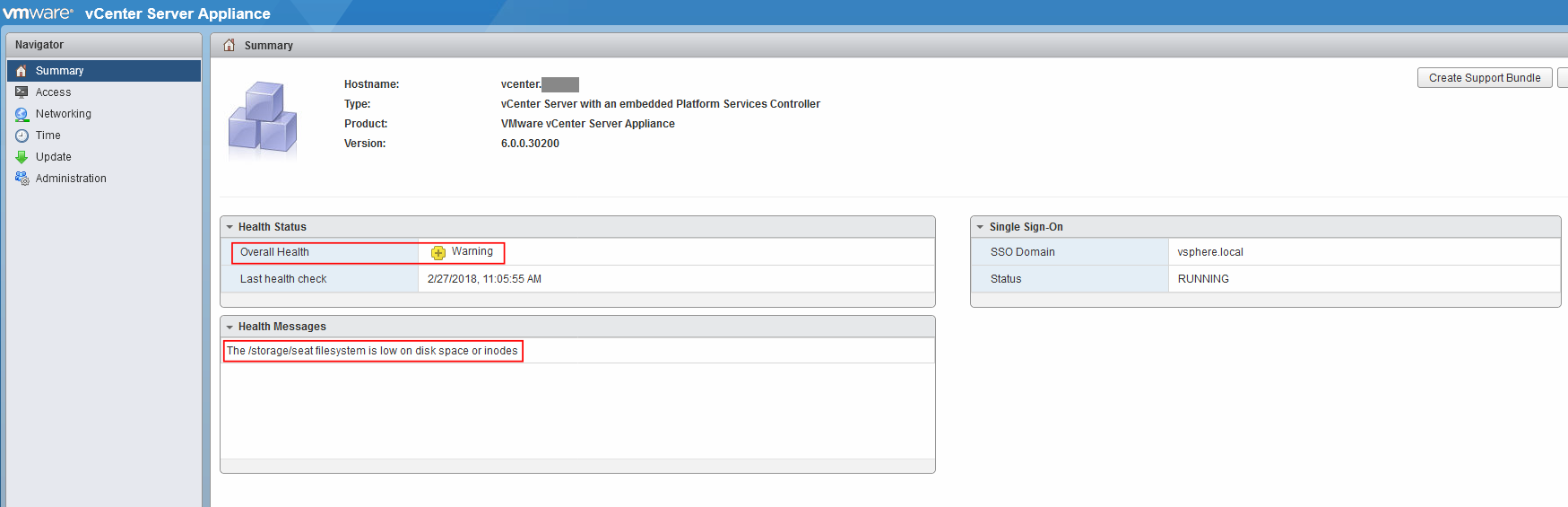
Nicméně stále nevíme, jaký je reálný stav zaplnění disku, proto se přihlásíme přes SSH a spustíme následující příkazy:
shell.set --enable true shell df -h
Měli bychom pak dostat přibližně takovýto výstup:
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 11G 5.3G 5.0G 52% /
udev 4.0G 164K 4.0G 1% /dev
tmpfs 4.0G 44K 4.0G 1% /dev/shm
/dev/sda1 128M 41M 81M 34% /boot
/dev/mapper/core_vg-core 25G 1.1G 23G 5% /storage/core
/dev/mapper/log_vg-log 9.9G 6.2G 3.2G 67% /storage/log
/dev/mapper/db_vg-db 9.9G 357M 9.0G 4% /storage/db
/dev/mapper/dblog_vg-dblog 5.0G 1.9G 2.9G 39% /storage/dblog
/dev/mapper/seat_vg-seat 9.9G 9.4G 0 100% /storage/seat
/dev/mapper/netdump_vg-netdump 1001M 18M 932M 2% /storage/netdump
/dev/mapper/autodeploy_vg-autodeploy 9.9G 151M 9.2G 2% /storage/autodeploy
/dev/mapper/invsvc_vg-invsvc 5.0G 167M 4.6G 4% /storage/invsvc
Z výpisu je již jasné, že došlo místo na svazku /storage/seat/ a je nutno buď místo uvolnit nebo navýšit. Na tomto konkrétním svazku se nachází databáze pro statistiky, události, alarmy a úkoly. Je tedy potřeba smazat záznamy v databázi, a protože již místo úplně došlo, tak není prostor pro vykonání nutných operací, proto prvně provedeme navýšení místa.
Navýšení diskového prostoru
1. zjistíme, který disk máme navýšit:
| Disk (VMDK) |
Výchozí velikost (Tiny VCSA) |
Přípojný bod | Účel |
| VMDK1 | 12GB | / (10GB) /boot (132MB) SWAP (1GB) |
Adresář zavaděče, je zde uložen kernel image a konfigurace zavádění |
| VMDK2 | 1.3GB | /tmp | Adresář dočasných souborů, generovaných nebo používaných službami vCenter serveru |
| VMDK3 | 25GB | SWAP | SWAP adresář |
| VMDK4 | 25GB | /storage/core | Adresář jádra, kde jsou ukládány výpisy z procesu VPXD |
| VMDK5 | 10GB | /storage/log | Log adresář pro ukládání všech protokolů |
| VMDK6 | 10GB | /storage/db | Adresář databáze VMware Postgres |
| VMDK7 | 5GB | /storage/dblog | Adresář logů databáze VMware Postgres |
| VMDK8 | 10GB | /storage/seat | Adresář VMware Postgres – statistiky, události, alarmy a úkoly |
| VMDK9 | 1GB | /storage/netdump | Adresář pro VMware Netdump collector – ESXi dumpy |
| VMDK10 | 10GB | /storage/autodeploy | Adresář pro balíčky používané při Auto Deploy – bezstavový boot ESXi hostů |
| VMDK11 | 5GB | /storage/invsvc | Adresář VMware Inventory Service, kde jsou uloženy konfigurační soubory xDB, Inventory Service bootstrap a konfigurační soubory Tomcat |
2. připojíme se přes host clienta – (https://FQDN-nebo-IP-adresa-ESXi-hosta/UI) a navýšíme velikost VMDK8
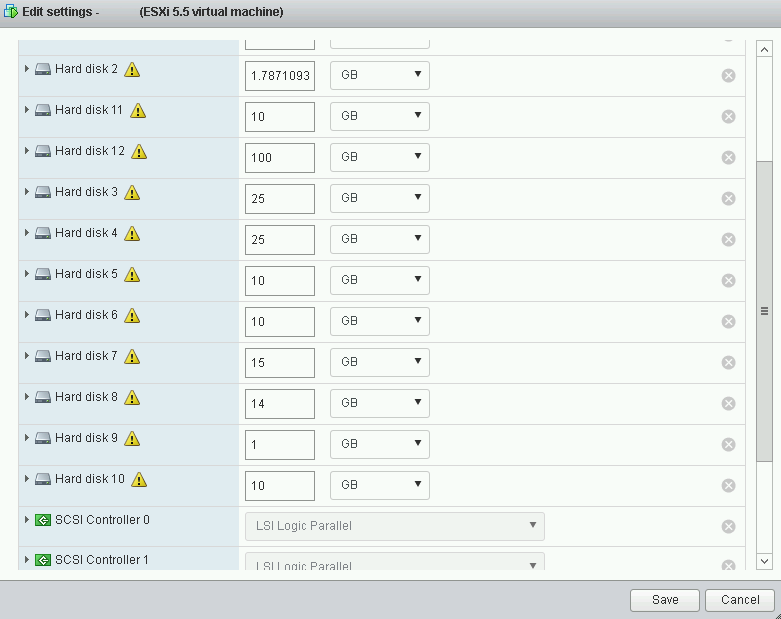
v našem případě jsem zvolil navýšení o 4GB, stačilo by ale i méně, navýšení provádíme pouze proto, aby nám bez problémů prošlo promazání databáze
3. přihlásíme se k vCSA přes SSH a spustíme následující příkazy:
shell.set --enable true shell
4. následujícím příkazem rozšíříme samotný svazek:
vpxd_servicecfg storage lvm autogrow
zpět bychom měli dostat následující odpověď:
VC_CFG_RESULT=0
5. kontrolu, že došlo k navýšení místa na svazku, provedeme příkazem:
df -h
a měli bychom dostat takovýto výpis, ze kterého je již patrné, že došlo k navýšení místa svazku:
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 11G 5.3G 5.0G 52% /
udev 4.0G 164K 4.0G 1% /dev
tmpfs 4.0G 44K 4.0G 1% /dev/shm
/dev/sda1 128M 41M 81M 34% /boot
/dev/mapper/core_vg-core 25G 1.1G 23G 5% /storage/core
/dev/mapper/log_vg-log 9.9G 6.2G 3.2G 66% /storage/log
/dev/mapper/db_vg-db 9.9G 357M 9.0G 4% /storage/db
/dev/mapper/dblog_vg-dblog 5.0G 1.9G 2.9G 39% /storage/dblog
/dev/mapper/seat_vg-seat 14G 9.4G 3.8G 72% /storage/seat
/dev/mapper/netdump_vg-netdump 1001M 18M 932M 2% /storage/netdump
/dev/mapper/autodeploy_vg-autodeploy 9.9G 151M 9.2G 2% /storage/autodeploy
/dev/mapper/invsvc_vg-invsvc 5.0G 167M 4.6G 4% /storage/invsvc
Promazání záznamů v databázi
1. stále jsme přihlášení k vCenteru přes SSH, pokud ne, přihlásíme se a spustíme příkazy jako v bodě 3. při navyšování diskového prostoru
2. zastavíme službu VPXD:
service vmware-vpxd stop
3. přejdeme do adresáře /opt/vmware/vpostgres/current/bin:
cd /opt/vmware/vpostgres/current/bin
4. přihlásíme se do vCenter Server Appliance database:
./psql -d VCDB -U postgres
5. promažeme záznamy v databázi:
TRUNCATE TABLE vpx_event CASCADE;
zpět bychom měli dostat následující odpověď:
NOTICE: truncate cascades to table "vpx_event_arg" NOTICE: truncate cascades to table "vpx_entity_last_event" TRUNCATE TABLE
6. opustíme vCenter Server Appliance database:
\q
7. uděláme poslední kontrolu místa:
df -h
a z výpisu již vidíme, že místo bylo uvolněno:
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 11G 5.3G 5.0G 52% /
udev 4.0G 164K 4.0G 1% /dev
tmpfs 4.0G 44K 4.0G 1% /dev/shm
/dev/sda1 128M 41M 81M 34% /boot
/dev/mapper/core_vg-core 25G 1.1G 23G 5% /storage/core
/dev/mapper/log_vg-log 9.9G 6.2G 3.2G 66% /storage/log
/dev/mapper/db_vg-db 9.9G 357M 9.0G 4% /storage/db
/dev/mapper/dblog_vg-dblog 5.0G 1.9G 2.9G 39% /storage/dblog
/dev/mapper/seat_vg-seat 14G 6.9G 6.3G 53% /storage/seat
/dev/mapper/netdump_vg-netdump 1001M 18M 932M 2% /storage/netdump
/dev/mapper/autodeploy_vg-autodeploy 9.9G 151M 9.2G 2% /storage/autodeploy
/dev/mapper/invsvc_vg-invsvc 5.0G 167M 4.6G 4% /storage/invsvc
8. nastartujeme zpět službu VPXD:
service vmware-vpxd start
nyní máme vCenter opět v kondici a vše funguje, jak má.